This post is a collection of my notes on Lucas Brutschy et al’s paper “Effective Serializability for Eventual Consistency”. A later version of this paper has been accepted to POPL’17.
Introduction
Serializability is a well-understood criterion to reason about
concurrent transactions. Enforcing serializability via pessimistic
concurrency control techniques, such as S2PL, is very expensive.
Papadimitriou shows that checking a transaction history
for serializability is NP-complete, hence optimistic concurrency
control methods are no good either. However, Papadimitriou also shows
that it is possible to construct efficient algorithms to detect
violations of stronger variants of serializability. One such
well-known variant is conflict-serializability. A history is
conflict-serializable iff it has no conflicts among write-read,
write-write and program-order dependencies. Conflict serializability,
being a syntactic check, can be implemented efficiently by algorithms
that detect cycles in the dependency graphs. However,
conflict-serializability is stronger than serializability in the sense
that it is possible for a history to exhibit conflicts in its
dependency graph, yet be observably equivalent to a serial schedule.
This may happen if the conflicts are not semantically relevant. An
example is the following history of three concurrent
transactions (T1, T2, and T3):
w1(A), w2(A), w2(B), w1(B), w3(B)
There is a write-write dependency from T1 to T2 w.r.t A, and
another write-write dependency from T2 to T1 w.r.t B. The cycle in
the dependency graph means that the history is not serializable.
However, considering that later writes to an object absorb the
effects of earlier writes, the schedule is observationally equivalent
to the following serial schedule:
w1(A), w1(B), w2(A), w2(B), w3(B)
Hence, the schedule is effectively serializable, although it is not
conflict-serializable. In the context of relational databases, where
reads and writes are the only atomic actions, overlooking absorption
is the main reason why serializable schedules are classified as
non-serializable. But as we raise the level of abstraction to more
sophisticated atomic actions, e.g., add or listLength,
commutativity also becomes a reason to relax the definition of
conflict-serializability. The main contribution of the paper is
therefore to relax the definition of conflict-serializability to
account for commutativity and absorption. The paper also generalizes
the definition of (relaxed) conflict serializability to be applicable
for histories generated by non-SC stores. Such histories, unlike the
totally ordered SC histories shown above, are only partially ordered.
Technical Development
Actions are atomic actions with possible return values, such as
x.set(0), x.add(2), x.get():2 etc. Action semantics is given as
prefix-closed set of legal action sequences. For example, x.set(0),
x.add(2), x.get():2 is a legal action sequence. The specification of
an action is a possibly-infinite set of such action sequences. Two
action sequences are equivalent (≡) iff they are legal in exactly
the same contexts. Thus x.set(0), y.set(1) and y.set(1), x.set(0)
are equivalent because whenever the former appears in a legal action
sequence, it can be replaced by the latter preserving the legality,
and vice-versa. Observe that the definition of the legality is
cleverly crafted to subsume the notion of observational equivalence;
two legal action sequences containing the same set of actions are
observationally equivalent. Thus, any transformation done on a
sequence while preserving legality results in a sequence that is
observationally equivalent.
Commutativity and absorption can now be specified in terms of
equivalent action sequences. Two actions u and v are commutative
iff uv ≡ vu. Likewise, v absorbs u iff uv ≡ v.
Since there is no need to consider order between adjacent commutative actions, we can relax such orders in an action sequence. The resultant partial order is called a trace. We furthermore divide the set of actions () into updates (), for which return values are not relevant, and queries (), for which only the return values are relevant. Authors assume that updates have not preconditions whatsoever, hence any action sequence containing only the updates is legal.
Let us now consider histories. As described above, SC histories are linear action sequences. However, under weaker levels of consistency, histories are only partially ordered w.r.t , the program order, , the visibility order, and , the arbitration trace. Visibility describes what updates are visible to what queries, and arbitration totally orders non-commutative actions (e.g., via timestamps). Since is a trace, commutative actions are not directly related by arbitration, but they may be related transitively via a non-commutative action. As with an SC history, the set of actions is partitioned into multiple transactions . Thus, a weakly consistent history (or schedule) is the tuple (note: we conflate the notions of history and schedule, although the paper doesn’t). For a weakly consistent schedule to be considered well-formed, it must satisfy the following properties:
- must be lower-finite and acyclic.
- Let be the action sequence of updates visible to a query order as per the arbitration order. Then, must be a legal action sequence.
- The set of updates invisible to a query must be finite (the liveness requirement of eventual consistency).
As an example, consider a query q that witnesses updates
{u1,u2,u3,u4,v1,v2}. Their collective arbitration trace might look
like the following:
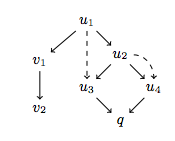
Solid arrows denote and dotted arrows denote absorption. The
two updates v1 and v2 are not dependencies of q because they do
not precede it in the trace order (maybe v1 and v2 are y.set(0)
and y.add(1), whereas q is x.get()), and therefore can be “moved
past” q. The update u2 is not a dependency of q either as it gets
absorbed by the adjacent update u4. But after that u1 and u3
become adjacent, and so u1 can get absorbed by u3. What remains
are the two dependencies u3 and u4 of q.
The algorithm to find dependencies of a query q is described below
with help of the above example:
- Start with a set of all updates visible to
qthat directly precedeqin .- For
qin the above figure, the set is{u3,u4} - Updates
v1andv2are thus already eliminated.
- For
- Lets call the set as . In each iteration, expand the
boundaries of by including updates that precede
those in the set in the order without being absorbed by
them (i.e., related to those in the set by a solid arrow, but not a
dashed arrow). If an update (
u) is absorbed by another update in the set, removeu, and relate all updates that precedeu(in ) to all updates that succeedu.- For the current example, the only update preceding the elements
in the set =
{u3,u4}isu2. However,u2is absorbed byu4, so we remove it from the trace and relateu1to bothu3andu4. - In the next iteration,
u1precedes the elements in , but it is absorbed byu3in , hence it too must be removed.
- For the current example, the only update preceding the elements
in the set =
- We iterate until there are no more updates left to be included in
.
- The final for the current example is thus
{u3,u4}.
- The final for the current example is thus
The set is the dependency set of q, and contains all
the updates that must be ordered before q in any serialization of
the original weakly consistent schedule. It is informative to note
that if we do not take commutativity and absorption into account, the
dependency set would have been equal to the visibility set of q.
The notion of dependency has a natural counterpart called anti-dependency. An anti-dependency of a query in a given schedule is an update not visible to the query but such that making it visible would turn it into a dependency.

Thus, the set , the anti-dependency set of q, contains
all the updates that must be ordered after q in any serialization
of the original weakly consistent schedule. Computing the set
of q is simple: find an update u not visible to q in
the original schedule, and make it visible. Now, run the above
algorithm to compute set of q. If contains
u, the u is an anti-dependency of q, otherwise not. Again, it is
informative to note that if we do not consider commutativity and
absorption, all updates not visible to q are its anti-dependencies.
Once we compute and for all the queries, a serial order can be obtained by topologically ordering the graph . If the graph contains a cycle, then we have a conflict, and the schedule is not serializable.
Evaluation
The evaluation is notable for its breadth. 33 TouchDevelop applications have been analyzed. TouchDevelop uses global sequence protocol (gsp) to implement a replication system with prefix consistency (stronger than causal). Nonetheless, even if the store is SC, serializability violations are possible because of dependency violations among transactions (groups of atomic actions). As our experience with RDBMS tranasactions informs, serializability violations are abound under weak isolation, and requiring serializability for all transactions is a giant overkill. As a thumb rule, authors assume that SER violations involving query transactions (transactions issued by the display code) as harmless, hence exclude them from the evaluation. Among the remaining transactions, many SER violations have been found. Some examples discussed in the paper:
- Tetris code where high-score is being locally updated (mutable integer). This is obviously incorrect. Fix is to basically turn the high score integer into an op-based data structure.
- Event management code where the app sorts the cloud-backed list of events by removing the events, sorting them locally, and re-inserting them. Fix is to either do it in a SER transaction, or to simply stop doing that. Sort locally whenever event list is being queried.
- A quiz game that allows a user to overwrite an existing user account due to incorrect uniqueness check. Fix is to use CAS.
- A Tic-Tac-Toe game that uses mutable datatypes all over. The fix is to use a data model that is op-based.
Another round of evaluation is done with TPC-C implementation on top of Riak (an EC store with no strengthening). Some violations:
- A
DELIVERYtransaction that updates a mutable balance. Obviously, one of the updates is lost when twoDELIVERYtransactions run concurrently. The fix is to use a CRDT counter for balance. DELIVERYtransaction also has a subsequentgetBalanceoperation, so even if the balance is a CRDT, SER violations still exist. However, this violation is ignored since it is harmless.- The percieved foreign-key violation between
ORDERSandNEW_ORDERStables manifests as an SER violation. The fix proposed is denormalization of data, although enforcing monotonic reads via QUORUM writes would fix the issue. - Two
NEW_ORDERtransactions assign same id to a transaction. The behaviour is not serializable, and the only fix is to use CAS.
Observations and Questions
- It is remarkable that testing could uncover uniqueness bugs and
foreign key bugs since they require concurrent transactions
to issue operations on very specific keys and ids (
uniqueness for example requires to randomly issuedSee comments).NEW_ORDERtransactions to insert an order with exact same id - Moreover, uncovering these bugs requires conflicting transactions to overlap in a specific manner. Such concurrent schedules are hard to trigger, aren’t they?
- This leads to the question: what is the test harness and testing methodology?
- Perceived foreign key violation has been uncovered by analyzing a query transaction. It is for this reason that I don’t feel comfortable excluding query transactions.
- With mutable data, lost updates are inevitable. That is, the
presence of
UPDATE ... SETqueries in weakly isolated transactions is itself a sufficient condition to witness SER violations. 4 of the 8 bugs discussed above fall into this category. The fix proposed in all the cases is to basically turn the mutable data into an op-based RDT. Assuming that we start we such an implementation, how many new bugs would be uncovered? What are the fixes? - It would be interesting to apply effective serializability criterion to replicated versions of stacks and queues. Experience tells us that replicating these data structures in a coordination-free fashion is quite tricky.